
https://megamaker.tistory.com/372
[DB][SQLD][2024] 2-1 SQL 기본 정리
https://megamaker.tistory.com/371 [DB][SQLD][2024] 1-2 데이터 모델과 SQL 정리https://megamaker.tistory.com/365 [DB][SQLD][2024] 1-1 데이터 모델링의 이해 정리이번에 SQLD 자격증을 공부하면서 뭔가 한번에 들어오는게
megamaker.tistory.com
ㄴ 이전 게시글
SQL 활용 - 세부 항목

서브 쿼리
서브 쿼리
하나의 쿼리 안에 또다른 쿼리가 존재하는 것
| 단일 값 반환(주로 SELECT 절에서 사용) | 스칼라 서브쿼리 |
| FROM 절 | 인라인 뷰 또는 동적 뷰 |
| WHERE 절, HAVING 절 | 중첩 서브쿼리 |
연관 서브쿼리
메인 쿼리의 속성이 포함
비연관 서브쿼리
메인 쿼리의 속성이 포함 X
스칼라 서브쿼리
단일 값을 반환하는 서브쿼리
주로 SELECT 문에서 사용

인라인 뷰
테이블명이 올 수 있는 곳에 작성 가능한 쿼리
FROM 절에서 사용
다른 테이블과 조인 시 반드시 별칭 사용

중첩 서브쿼리
WHERE 절과 HAVING 절에서 사용하는 서브쿼리
단일행 서브쿼리
서브쿼리의 결과가 1개만 반환됨
단일행 서브쿼리 연산자
| = |
| <> |
| < |
| <= |
| > |
| >= |
다중행 서브쿼리
서브쿼리의 결과가 여러 행이 반환
다중행 서브쿼리 연산자
| IN |
| ANY |
| ALL |
| SOME |
| EXISTS |
다중 컬럼 서브쿼리
서브쿼리의 결과로 여러 컬럼을 반환
메인 쿼리와 서브쿼리의 비교하고자하는 컬럼 수가 같아야 함
집합 연산자
집합 연산자
쿼리의 결과를 하나의 집합으로 간주하고 각 집합에 대한 연산을 수행
- 두 집합의 컬럼 수, 순서, 데이터 타입 일치해야 함
- ORDER BY는 전체 결과에 대해서 마지막에 한 번만 작성
| UNION | 합집합 / 중복 제거 |
| UNION ALL | 합집합 / 중복 O |
| INTERSECT | 교집합 / 중복 제거 |
| MINUS / EXCEPT | 차집합 / 중복 제거 |
그룹 함수
그룹함수
데이터 집합을 그룹화하여 각 그룹에 대한 요약 통계 정보를 계산하는 함수
- 주로 GROUP BY와 함께 사용
- NULL 제외하고 계산
| 집계 함수 | COUNT, SUM, AVG, MAX, MIN 등 |
| 소계 함수 | ROLLUP, CUBE, GROUPING SETS 등 |
집계 함수
| COUNT | 행의 수를 반환 문자, 숫자, 날짜 모두 전달 가능 *는 모든 행의 수를 반환 -> WHERE 속성 IS NOT NULL로 특정 속성 NULL인 데이터 제외 가능 COUNT에 전달되는 값이 NULL뿐이어도 결과는 0임!! |
| SUM | 총합 |
| AVG | 평균 |
| MIN | 최소 |
| MAX | 최대 |
| VARIANCE | 분산 |
| STDDEV | 표준편차 |
소계 함수 - GROUPING BY 절에 사용하는 함수
- ROLLUP(A, B, C)
ABC
AB
A
총합계
- CUBE(A, B, C)
ABC
AB
BC
AC
A
B
C
총합계
- GROUPING SETS(A, B, C) - 총합계 안 나옴!!! 나오게 하려면 A, B, C에 ROLLUP 또는 CUBE를 사용 OR ()를 입력
A
B
C
윈도우 함수
윈도우 함수
서로 다른 행을 비교할때 사용하는 함수 / 서브 쿼리로도 가능
| 순위 함수 | RANK, DENSE_RANK, ROW_NUMBER |
| 집계 함수 | SUM, MAX, MIN, AVG, COUNT |
| 행 순서 함수 | FIRST_VALUE, LAST_VALUE, LAG, LEAD |
| 비율 함수 | CUME_DIST, PERCENT_RANK, NTILE, RATIO_TO_REPORT |
문법

ROWS - 같은 값이어도 각 행씩 연산
RANGE - 기본값 / 같은 값이면 묶어서 한번만 연산
BETWEEN A AND B
A
CURRENT ROW - 현재 행부터
UNBOUNDED PRECEDING - 첫 번째 행부터 / 기본값
N PRECEDING - N번째 행 이전부터
B
CURRENT ROW - 현재 행까지 / 기본값
UNBOUNDED FOLLOWING - 마지막 행까지
N FOLLOWING - N번째 행 이후까지
아무것도 안 적으면 첫 번째 행부터 현재 행까지가 기본으로 적용됨
순위 함수
RANK - 순위를 구함 / 동순위 이후 등수는 스킵 ex) 1 2 2 4
DENSE_RANK - 순위를 구함 / 동순위이더라도 이전의 순위에 이어서 진행 ex) 1 2 2 3
ROW_NUMBER - 연속된 행 번호 / 그냥 단순히 행 번호를 나열함 ex) 1 2 3 4
행 순서 함수
FIRST_VALUE - 처음 값 출력
LAST_VALUE - 마지막 값 출력
주의!! 위 두 함수는 각각 무조건 최소와 최대를 출력하는게 아님 / 정렬 순서에 따라 달라짐
LAG - 이전 행 값 가져옴
LEAD - 다음 행 값 가져옴
비율 함수
NTILE - 그룹을 나누어 그룹 번호를 출력 / 그룹 크기가 딱 나누어 떨어지지 않으면 첫 번째 그룹부터 크기가 더 크게 할당됨 ex) 8개의 행을 3그룹으로 나누면 3, 3, 2로 나뉨
PERCENT_RANK - 전체 COUNT 중 상대적인 위치를 0 ~ 1 사이로 출력

RATIO_TO_REPORT - 대상 속성에 대한 비율을 출력

CUME_DIST - 현재 행과 같거나 작은 행들의 누적 백분위 / 0 ~ 1 사이로 출력

Top N 쿼리
Top N 쿼리
특정 조건을 만족시키는 N개의 행을 추출할 때 사용
- ROWNUM - 출력된 데이터 기준 행 번호 부여 / 가상으로 부여되는 번호이므로 1부터 순서대로 포함되는 숫자 조건이 아니면 <, >, = 등 사용 불가
- TOP N (SQL Server) - SQL Server에서 상위 n개 추출 / WITH TIES로 동순위 출력
- FETCH - 출력 행의 수를 제한 / ORDER BY 뒤에 사용
| OFFSET | 건너뛸 행의 수 |
| N | 출력할 행의 수 |
| ROW / ROWS | 굳이 단수 복수 구분 안 해도 됨 |
| FETCH | 출력할 행의 수를 전달 |
| FIRST | OFFSET을 사용 안 할 때, 처음부터 N행 |
| NEXT | OFFSET을 사용했을 때, 건너뛴 행 다음부터 N |
사용 예시)

계층형 질의와 셀프 조인
계층형 질의 & 셀프 조인
자기 자신의 테이블과 조인해서 행과 행 사이의 계층을 나타냄

- START WITH - 시작 노드
- CONNECT BY [NOCYCLE] PRIOR - 부모 자식 관계 조건 설정 NOCYCLE이 붙으면 순환되는 상황 방지
PRIOR붙은 곳(부모ID)부터 시작, 다른 행 중에서 안 붙은 곳(ID)으로 이동 <- 반복이라고 생각하면 됨
가상 컬럼
- LEVEL - 1부터 시작하여 깊이를 출력
- CONNECT_BY_ISLEAF - 최하위 노드인지 여부 (맞으면 1, 아니면 0)
가상 함수
- SYS_CONNECT_BY_PATH(속성, 구분자) - 이어지는 경로 출력
- CONNECT_BY_ROOT 속성명 - 루트 노드의 속성값
- ORDER SIBLIGS BY 컬럼 - 같은 LEVEL간 정렬
- CONNECT_BY_ISCYCLE - 순환이 발생했는지 여부
PIVOT 절과 UNPIVOT 절
LONG DATA
일반적으로 사용하는 RDBMS에서 사용하는 데이터가 행으로 쌓이는 구조
다른 테이블과 조인 가능

WIDE DATA
엑셀 등에서 주로 사용하는 데이터가 넓게 저장되는 방식
다른 테이블과 조인 불가
일반적으로 요약의 목적으로 사용
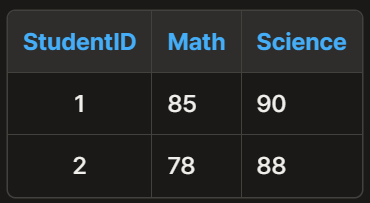
PIVOT
LONG DATA -> WIDE DATA
- STACK 컬럼
- UNSTACK 컬럼
- VALUE 컬럼
WIDE 데이터로 바꾸면 아래와 같이 바뀜

위 예시에서 StudentID포함 아래로 쭉 STACK 컬럼
Math, Science, History가 UNSTACK 컬럼
나머지 1 1 0 1 1 1이 VALUE 컬럼
예시


PIVOT(VALUE컬럼 FOR UNSTACK컬럼 IN(값 ...))
STACK 컬럼 명시가 안 되어 있는데 FROM 절에 있는 테이블의 UNSTACK과 VALUE 컬럼을 제외한 모든 컬럼이 STACK 컬럼이 됨
그래서 서브쿼리로 필요한 컬럼만 가져옴

UNPIVOT
WIDE DATA -> LONG DATA
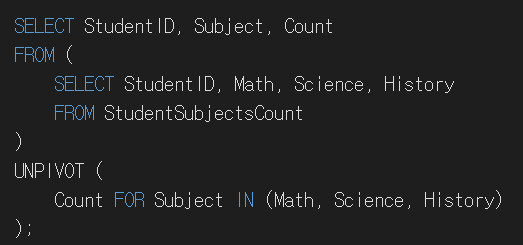
다시 LONG DATA로 바꿀 때 STACK 컬럼명은 새로 만들어야 하니 새로 지정해줘야 함
PIVOT, UNPIVOT은 글로 설명하기 어려워서 유튜브 강의를 보는 것을 추천합니다.
정규 표현식
https://megamaker.tistory.com/127
정규 표현식(Regular expression)
정규 표현식(Regular expression)이란?정규 표현식은 특정 규칙이 있는 문자열에서 원하는 조건으로 일치하는 그룹 결과를 얻을 수 있는 형식 언어이다. 문자열문자열 자체를 입력하면 해당 문자열
megamaker.tistory.com
| REGEXP_LIKE(컬럼, 정규 표현식) | ㅇ 정규표현식을 만족하는 문자열을 포함하고 있으면 참 |
| REGEXP_SUBSTR(문자열, 정규표현식 [, 시작위치(최소는1)] [, n번째결과]) | ㅇ 시작위치부터 정규표현식에 맞는 n번째 결과를 잘라서 반환 ㅇ 시작위치와 n번째 결과 생략 시 처음부터 첫 번째 결과를 반환 |
| REGEXP_REPLACE(문자열, 정규표현식 [, 바꿀 문자열]) | ㅇ 문자열에서 정규표현식을 이용하여 조건에 맞는 부분을 바꿀 문자열로 변경 ㅇ 뒤에 옵션이 더 있지만 시험에 그렇게 어렵게 안 나올거 같아서 생략 |
다음 게시글
https://megamaker.tistory.com/375
[DB][SQLD][2024] 2-3 관리 구문 정리
https://megamaker.tistory.com/374 [DB][SQLD][2024] 2-2 SQL 활용 정리https://megamaker.tistory.com/372 [DB][SQLD][2024] 2-1 SQL 기본 정리https://megamaker.tistory.com/371 [DB][SQLD][2024] 1-2 데이터 모델과 SQL 정리https://megamaker.tistor
megamaker.tistory.com
'공부 > 데이터베이스' 카테고리의 다른 글
| [DB][SQLD][2024] SQLD 개념 요약 정리 (0) | 2024.08.23 |
|---|---|
| [DB][SQLD][2024] 2-3 관리 구문 정리 (0) | 2024.08.22 |
| [DB][SQLD][2024] 2-1 SQL 기본 정리 (0) | 2024.08.19 |
| [DB][SQLD][2024] 1-2 데이터 모델과 SQL 정리 (0) | 2024.08.18 |
| [DB][SQLD][2024] 1-1 데이터 모델링의 이해 정리 (0) | 2024.08.12 |