
2진수의 표현 방법
컴퓨터에서 2진수를 표현하는 방법은 여러가지가 있다.
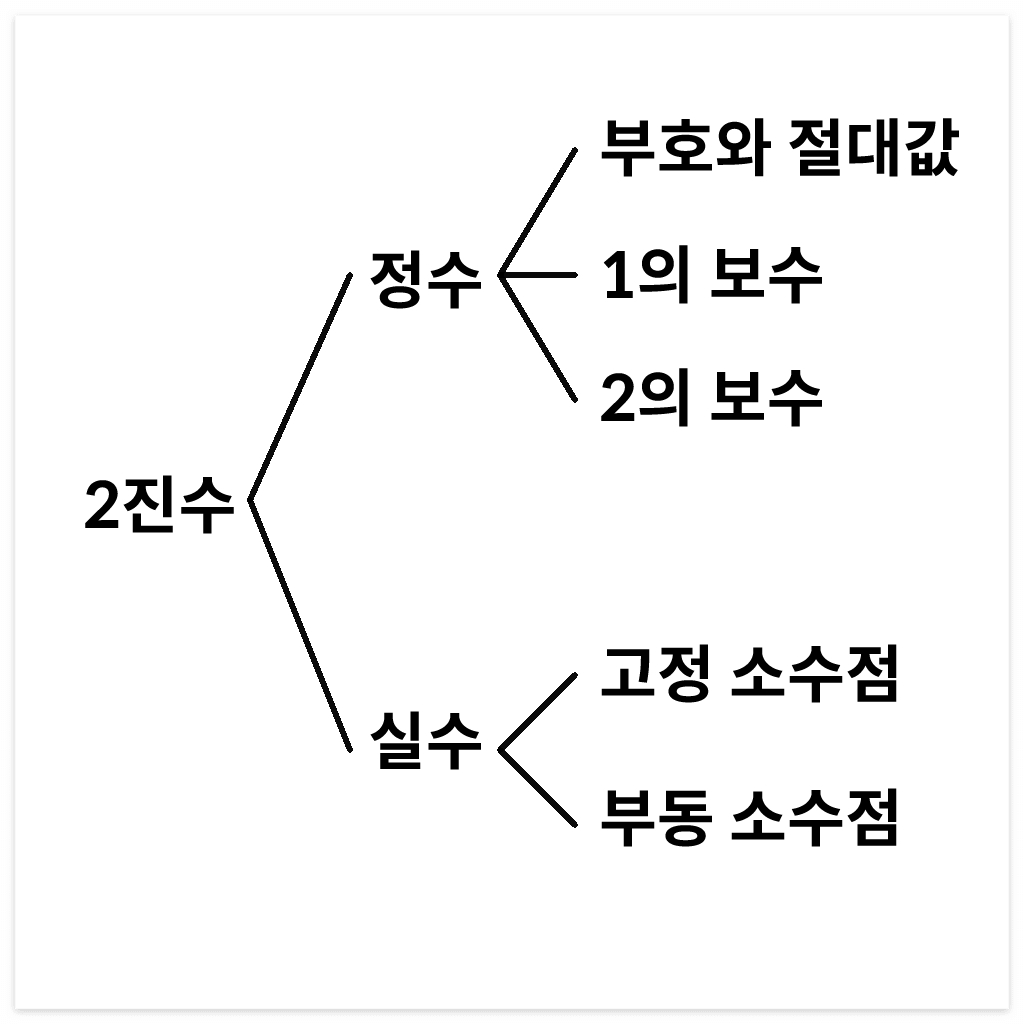
정수 표현 방법
정수의 표현 방식으로는 부호 절댓값, 1의 보수, 2의 보수가 있는데 간단히 살펴보자면
부호와 절댓값은 최상위 1비트만 부호 비트로 사용하고 나머지 비트들로 값을 표현한다.
1의 보수는 부호비트를 사용하지 않고 음수를 표현할 때 비트를 모두 1로 만든 2진수 값에서 해당 양수의 값을 빼서 구한다. 즉, 0인 비트를 1로, 1인 비트를 0으로 바꾸면 된다.
2의 보수는 1의 보수의 값에 1을 더해주면 된다.
부호와 절대값과 1의 보수 표현법은 +0과 -0이 동시에 존재하기 때문에 문제가 생길 수 있다. 하지만 2의 보수는 -0은 존재하지 않고 바로 0이 아닌 음수부터 시작하기 때문에 이 문제를 해결할 수 있으며 필요 없는 0 한 자리가 빠진 대신 음수를 한 자리 더 표현할 수 있다.
실수 표현 방법
실수의 표현 방식은 두 가지가 있다.
고정 소수점
고정 소수점은 부호, 정수부, 소수부를 나누어서 고정된 공간에서 값을 표현하는 방법이다.
부호는 양수는 0, 음수는 1로 표현한다.
정수부는 우측부터 좌측으로 채워나가며, 비어있는 공간은 0으로 채운다.
소수부는 좌측부터 우측으로 채워나가며, 마찬가지로 비어있는 공간은 0으로 채운다.
16비트 공간에서의 10진수 23.5625를 예로 확인해보자. 해당 수를 2진수로 변환하면 10111.1001이다.

부호 부분과 비어 있는 부분을 채우면 아래처럼 된다.

고정 소수점 표현은 표현할 수 있는 수의 범위가 크지 않아 효율적이지 않으므로 잘 사용되지 않는다.
부동 소수점
부동 소수점은 IEEE 754 기술 표준을 따라 표현한다. 대부분의 장치들은 해당 표준을 통해 실수를 표기한다.
32비트를 단정도 표현(Single-precision)이라 하고, 64비트를 배정도 표현(Double-precision)이라고 한다.
간단한 구성을 보면 부호 비트, 지수부, 가수부로 나뉘어져 있다.


10진수 14.625를 2진수로 변환하면 1110.101이다. 이를 부동 소수점으로 표현하면 맨 앞의 비트 1 이후의 비트들(110101)은 가수부 비트에 저장되고 지수부에는 10진수 3의 이진 표현인 11이 저장된다. 그런데 실제로 부동 소수점 변환기를 사용하여 변환을 해보면 지수 부분이 00000011가 아닌 1000010으로 저장된 것을 알 수 있다. 왜 이런 결과가 나온 것 일까?
그 이유는 바로 bias 때문이다.
만약 부동 소수점 표현으로 변환할 수가 1보다 작은 수라고 가정해보자. 10진수 0.625을 예로 들면 이를 2진수로 변환하면 0.101이다. 부동 소수점은 가수부의 맨 앞을 1로 통일시켜야하는데 지금 상태로는 맨 앞 비트가 0이다. 그렇기 때문에 1로 통일시키려면 뒤의 비트를 앞으로 당겨야하고 그로 인해 지수부의 값이 음수가 되는 것이다. 지수부의 부호 처리를 하기 위해서는 다른 처리를 해야하고 컴퓨터가 2의 보수법으로 대소를 비교하기 쉽지 않기 때문에 bias라는 것을 이용하여 지수부를 표현하는 것이다.
단정도 표현에서는 지수부가 8bit이기 때문에 부호 없는 표현 방식에서 표현 할 수 있는 범위는 0 ~ 255이다. 그렇기 때문에 표현 범위의 균형을 맞추면서 값을 나눌 수 있는 방법이 bias를 사용하는 것이다.
/*bias가 왜 단정도 표현에서는 128이 아니라 127인지 찾아보았다. 2의 보수 표현과 bias는 관계가 없다는 것은 알았으나 정확히 왜 2^(지수부bit -1) 인지는 찾지 못했다... 대부분의 의견은 무한대나 NaN의 표현과 표현 범위의 균형을 맞추기 위해서라고 한다.*/
어쨌든 그렇게 되면 지수부의 범위는 -127 ~ 128이 된다. 여기에 bias를 더해주게 되면 0 ~ 255의 범위를 가지게 되어서 이를 최종적으로 지수부에 입력해주는 것이다.
실수 표기 시 문제
부동 소수점 표현으로 실수를 표현한다고 해도 이를 무한정으로 표현할 수는 없다. 어느정도 한계가 있는데 이 때에는 표현할 수 없는 자릿수의 값을 반올림하여 표현한다. 그래서 실수 계산을 할 때 실수 자료형의 값이 정확하게 맞지 않는 이유가 이 때문이다.
float의 표현 범위를 계산해보자. float은 32bit 자료형으로 단정도 표현을 사용해서 계산한다. 단정도 표현에서 지수 비트는 8bit인데 지수의 범위는 -127 ~ 128이다. 2^-126 ~ 2^128의 범위를 가지게 되는데 이는 대략 1.175e-38 ~ 3.403e+38의 범위이다. -127이 왜 -126이 되었는지는 정확하게 찾지는 못했지만 무한대나 NaN의 경우를 제외한 것 같다.
double의 표현 범위는 지수 비트가 11bit이므로 -1023 ~ 1024의 범위를 갖는다.
그러므로 2^-1022 ~ 2^1024 = 2.225e-308 ~ 1.798e+308의 범위를 갖게 된다.
float과 double의 오차 없이 값을 얻을 수 있는 정확도는 각각 6자리, 15자리인데(일부 수의 경우 더 높은 정확도로 계산할 수 있다.) 이 정확도를 넘어가는 값을 표현하게 되면 값이 근사치로 계산되어 원래의 값과 달라지는 것이다.
실수끼리의 연산을 원하는대로 하기 위해서는 몇 가지 회피 방법이 필요하다.
두 실수 비교 시 일정 오차 기준 내인지 확인한다.
d1과 d2라는 실수가 있을 때 두 실수가 같은지 확인하려고 한다. 이때 일정 오차 내이면 같은 수라고 판단하는 방식을 사용할 수 있다.
예를 들어 d1 = 2.80252252, d2 = 2.802522519 라고 하면 d1 - d2의 절댓값을 구해 임의로 정한 오차 기준인 1e-8보다 작으니 같은 수라고 볼 수 있다.
다른 방법으로는 상대 오차가 있다.
예를 들어, 같은지 비교를 원하는 수의 크기가 큰데 사람이 풀었을 때 같아야할 연산을 했다고 하면 수학적으로 값의 변경이 없어야할 식의 결과가 컴퓨터가 연산하면서 오차가 발생할 수 있다. 그 예가 다음과 같다.

x의 값이 작다면 단순히 위의 방법으로 비교가 가능하나 x의 값이 클 경우에는 10^20과 비교하기도 전에 오차가 발생하게 된다. 값이 크면 그에 따른 오차도 커지게 되므로 조심해야 한다.
이 문제를 해결하기 위해 비교할 실수의 크기들에 비례한 오차 한도를 정하는 방법과 상대 오차를 사용하는 방법을 이용할 수 있다.

어떤 방법을 써야할지 잘 모르겠을 때 최후의 방법으로 숫자를 String으로 변환하여 직접 노가다해서 비교하는 방법도 있다...
해당 글은 알고리즘 문제 해결 전략 도서를 읽고 공부한 내용을 정리한 글입니다.